When considering the environmental impacts of AI, we shouldn’t just pay attention to model training and inference, but also pay attention to the way in which scraping and crawling by AI bots place stress on broader internet infrastructure. Tim explains how these new behaviours have an impact on carbon emissions, as well as on our work at Green Web Foundation, and some steps that webmasters can take to mitigate their most problematic impacts without harmful side effects.
We’ve written before on the Green Web Foundation blog about our evolving attitudes to AI technologies, their environmental impacts, and how (if at all) they can be used responsibly or sustainably. As we noted in our piece on adoption, hype, refusal and resistance, we try not to take an intransigent position on AI: we’re not only interested in advocating principled resistance to harmful AI technologies, but also in aiding the development of sustainable alternatives, and supporting more critical and responsible practices with them.
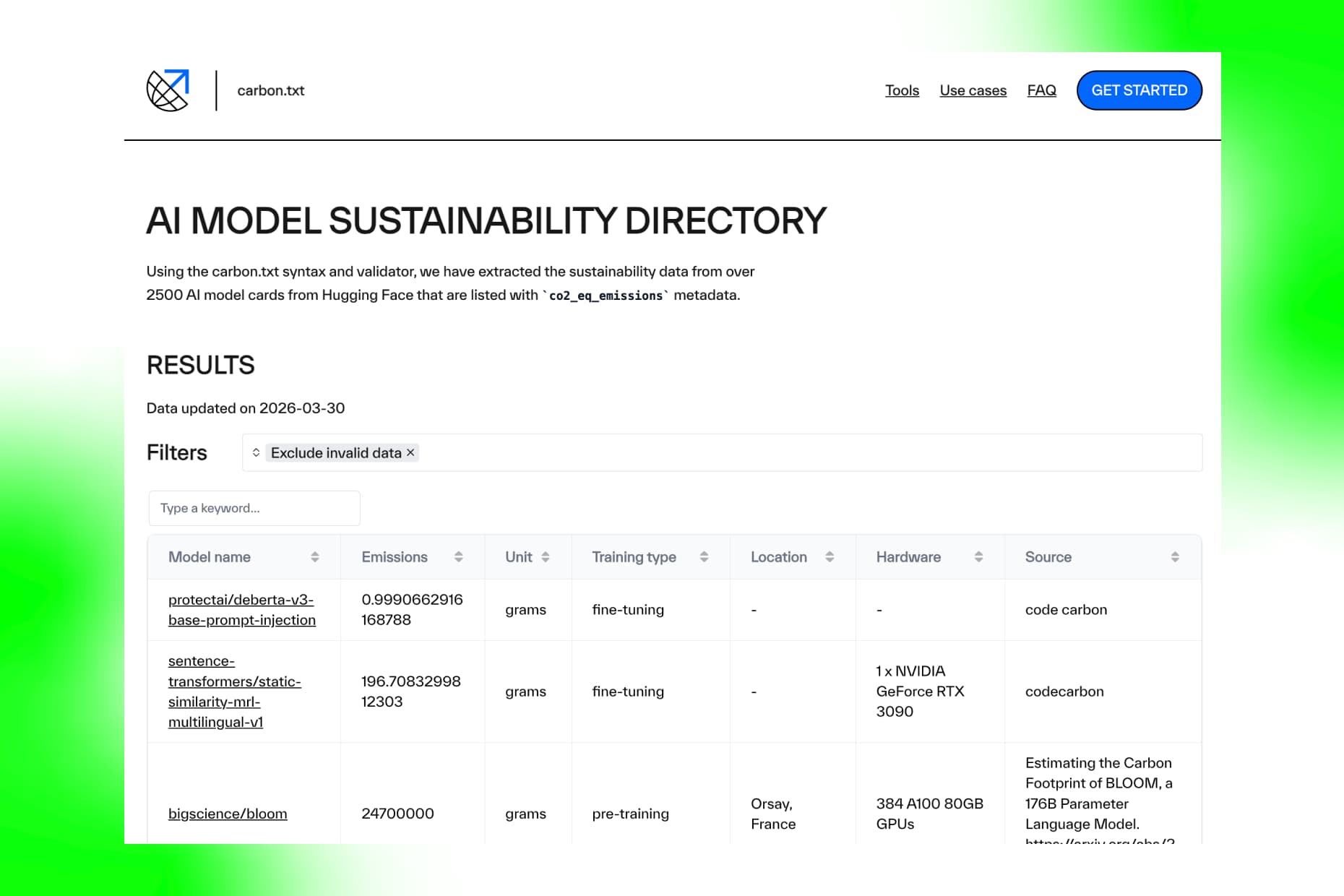
One of the reasons for this, is that whether you’re resisting AI, developing sustainable alternatives to it, or looking for ways to engage with it responsibly, you have a similar need for reliable, transparent, easily accessible information about its impacts in order to make informed decisions. Making access to this information is one of the things that we at Green Web Foundation focus on – through projects such as carbon.txt which aim to make sustainability data about digital services transparent, discoverable and reusable.
For instance, our work to include AI model cards as a supporting document in carbon.txt, and the AI sustainability directory we produced as a result, allow users (and refusers) of AI services to make an informed decision about their usage, and to identify the services with the least environmental impact.
Ai impacts, beyond the chat window
However, we’re also realising that it’d be a mistake to only concentrate on the impact of AI in use as part of this work – we interact, often unknowingly, with AI systems in a multitude of way, that don’t necessarily involve sitting in front of a chat window writing out prompts. The behaviour of these systems is increasingly making itself felt in other ways, at the level of infrastructure, through the web crawling and scraping used to create their training sets, and the behaviour of AI “agents” acting on behalf of their users.
Two cases in point – the increases in HTTP traffic caused by AI agents acting autonomously are stressing the infrastructures of major websites such as GitHub, and some large publishers are blocking otherwise legitimate web crawlers such as the Wayback Machine, due to concerns over AI scraping.
At GWF, we’re in an interesting position, as we’re impacted both by this sort of high volume scraping, and also by the more conservative blocking techniques used by web masters to combat it. A few weeks back we experienced outages on many of our systems, due to a collection of machines from a large cloud provider making hundreds of requests per second to our datasets website, continuously, over the course of several days. Due to this, we ended up adding an anti-scraping protection service on our CDN, which attempts to ban automated traffic by requiring requests from suspect IPs to resolve a CAPTCHA before accessing the site. However, this was a decision we took extremely reluctantly for several reasons. Firstly, relying on CDN services with anti-bot protection risks centralising the infrastructure of the internet, and making it more brittle and vulnerable to failures such as the cloudflare outage of November last year, but also because these types of protections are extremely heavy handed, and prohibit legitimate use of automatic bots, scrapers and crawlers.
Scrapers, crawlers and bots
This is the second way in which we are impacted at GWF – as we also rely on services which make automated HTTP requests as part of our day to day work. The Green Web Check service makes a request for the carbon.txt file at the domain you check, which enables us to identify whether or not that domain is hosted by a verified green provider. We’ve found that these requests are often refused outright by some providers, meaning that their green web check results can erroneously show as being “not green” when in fact they’re verified green providers.
We sympathize with the providers who block these requests, as we’ve had to deal with problematic bot traffic ourselves, and also because the environmental impacts of this additional traffic are considerable. When we think about the emissions impact of AI, we tend to imagine the emissions incurred during training and inference, but an out of control web crawler making millions of extra requests to web pages (remote-controlling a real browser, which loads javascript, stylesheets and renders images) is also considerable. It makes sense from both a pragmatic and environmental point of view to try and mitigate this.
This leaves us in a bind, though – how can we ensure that legitimate automated traffic (essential to so many web services, including our own Green Web Check) continues to work successfully, while blocking the most egregiously abusive bot activity and scraping?
Making Responsible Requests
We spoke to Julien Nioche, a web crawling and green software expert, who is the original author and one of the maintainers of Apache StormCrawler, a scalable open source web crawling framework. Julien gave us some useful advice, starting by underlining the difference between “crawling” and “scraping”. “Crawling” being an organized, horizontal, trawl of every page on the web, and “scraping” a targeted search for specific information, often from a specific site.
Julien also highlighted the importance of being a “polite citizen of the web”, when engaged in crawling or scraping, or using bots in general – ensuring that requests to a single host are made at a reasonable rate, actively adding a delay between each one, and providing a User-Agent header which accurately describes who is responsible for the the request, the purpose it will be used for, and linking to a page with more information, including details on how to opt out. Finally, it’s crucial to ensure that you respect any restrictions set out in the robots.txt file on the site you’re requesting.
In turn, it’s important for web masters and systems administrators to proactively review and understand the traffic which arrives at their site, and attempt not to be too heavy-handed in their response. Checking the user agents for your incoming traffic, and proactively, and selectively allowing and denying the traffic you want to accept or refuse, using mechanisms such as robots.txt and targeted IP blocks, allows a healthy web ecosystem while also reducing the extra load from malevolent or poorly configured scrapers.
In our own work, we’re attempting to put these ideas into practice, and in particular have published a page (linked to in our User Agent headers), which explains our use of automated HTTP requests at the Green Web foundation. If you’re a systems administrator or webmaster, or one of our verified hosting providers, we encourage you to take a look, and to help us in our mission by allowing traffic from our services to yours.
Finally, dialogue and communication between service providers and operators of crawlers and scrapers is key, and therefore our support team will always be happy to hear from users of our datasets, and hosting providers impacted by our services, in order to improve our systems and address your concerns. You can get in touch with us via the support form.