As part of a recent workshop we held at the Green IO Singapore conference, we made updates to the carbon.txt syntax to allow AI model information to be disclosed. In this post, our man in Asia, Fershad Irani, introduces this new disclosure type, shows how it can be used to choose sustainable models and demonstrate best practices, and shares a brand new directory we have built with it.
Most coding projects will contain a README.md file with details about the project, technical specifications, and instructions for getting started/running the project. This idea has been picked up in the world of large language models (LLMs) and rebranded as “model cards“. The concept was popularised by Hugging Face – the open source machine learning model community.
Hugging Face hosts over 2.7 million open source models and is a source for finding models in many of the most popular open source tools in the rapidly evolving artificial intelligence (AI) ecosystem. The great thing about the model cards syntax is that it allows for model developers to share structured metadata that can be parsed by machines to better understand the capabilities and background of different models. Hugging Face uses this metadata to enable filtering on their site. That’s pretty useful when you’ve got 2.7 million models to go through.
For us, at Green Web Foundation, the ability to extract meaningful sustainability information from structured data is one of the core ideas behind our carbon.txt project. With the growing use of AI by organisations, the ability to marry the structured data of AI model cards with carbon.txt to enable people to make better informed decisions about the models they use was one we wanted to explore.
The essence of an idea
This year, we were asked by the organisers of the Green IO Singapore conference to do a workshop bridging AI and our core work. Luckily, I work with an amazing group of people here at Green Web Foundation. When I went to them with the question “how do I fill 25 minutes with a talk about AI that also allows us to get visibility for carbon.txt?” they helped come up with a few different ideas we could explore.
Tim, who leads the technical development work on carbon.txt, suggested one idea that resonated with us – could we use carbon.txt as a way to surface emissions data associated with model training? That sounded cool, webby, and would also give us something to talk about. The problem was, at that time there was no clear way to highlight AI model data in a carbon.txt file, and no way for the tooling we’ve built to parse that information either.
Tim, as he does, got to work on a prototype.
AI Model Cards in carbon.txt
Tim’s work resulted in some really promising results.
In not much time, Tim had a working prototype of an updated carbon.txt syntax that allowed for the disclosure of AI training data through model cards. He had also built a plugin for our carbon.txt validator which could parse these disclosures and return the carbon emissions structured data present in the model card. The plugin was based on the Hugging Face’s specification for reporting training carbon emissions in model card metadata.
Using AI Model cards in carbon.txt to disclose training emissions
The updated carbon.txt syntax (version 0.5) includes a new organisational disclosure document type – doc_type: 'ai-model-card'. Using this document type, along with a URL of model card (README.md) makes a valid disclosure for training of AI models.
version="0.5"
last_updated=2026-04-08
[org]
disclosures = [
{ doc_type = 'ai-model-card', url = 'https://huggingface.co/bigscience/bloom/raw/main/README.md', title = "bigscience/bloom model card" }
]An example carbon.txt disclosure for the bigscience/bloom model on Hugging Face.
What about users of AI models?
The code snippet above is how you would reference a model card from within a carbon.txt file if you are the organisation that trained it.
But the majority of organisations are probably using AI models, most likely from a hosted service. What/how should they disclose the training data for these models as part of the services they use?
This is still an open question, and one that we hope to explore in the coming months. Right now, we are thinking about something along the lines of the code snippet below. But we’re open to ideas, so if you have any please let us know!
What can we do with these disclosures?
There are a few upsides (we believe) to allowing the disclosure of AI model training data in carbon.txt files:
- Have a single place where the companies building AI models can publish data about the models they build and their organisation. Let’s dream of a future where AI model providers like OpenAI, Anthropic, Mistral and others publicly disclose data about the training of their models on their own domains (e.g.
openai.com/carbon.txt). - Enable users of models to publicly demonstrate they are following best practice when selecting models such as the guidance that is included in the ITU’s Guidelines for Assessing the Environmental Impact of Artificial Intelligence Systems. Understanding the training impacts of the AI systems you use is a big part of this.
- Identify models which claim to have sustainability data but are missing some fields, or have incorrectly formatted the metadata in their model cards.
- Create an easier way for people to compare the sustainability data of different AI models before they choose to use them.
We’ve already built a tool to help with the last two! So with that, let me introduce you to the AI Model Sustainability Directory.
Sustainability data for all models on Hugging Face in one place
One idea that came up when we initially discussed referencing AI model cards in carbon.txt was the idea that we could create a directory of AI models and even build some kind of scoring system based on the sustainability data contained in their model cards.
After some initial research on how to get the information that would be needed to list Hugging Face models and send their model cards to the carbon.txt API, I had a first version of a directory coded up in a few hours. A few iterations later, we’re ready to share a beta version of a tool we hope can be useful for responsible technologists who are looking at AI models.
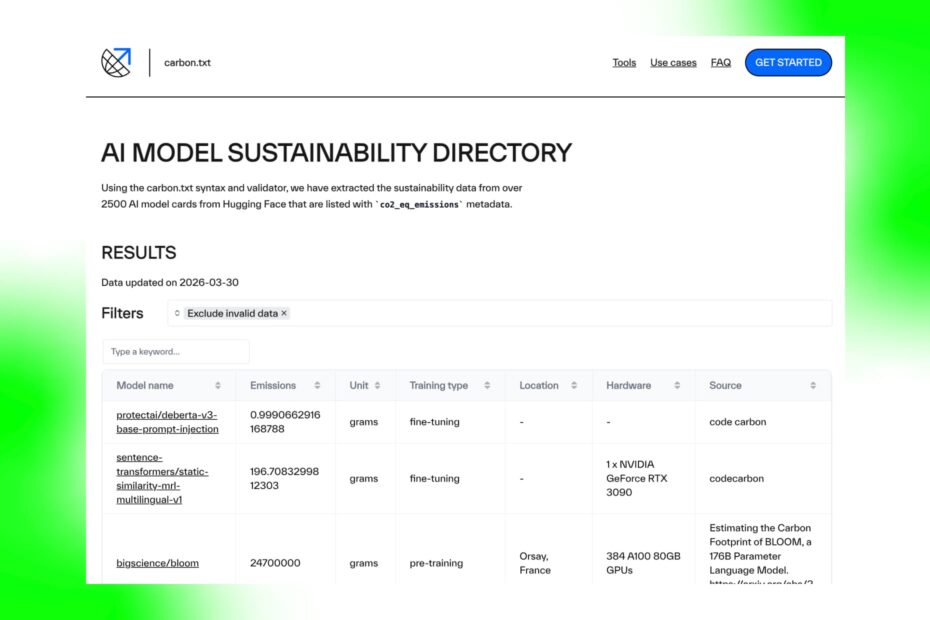
What’s in the directory?
The AI Model Sustainability Directory contains information for the 2500+ models hosted on Hugging Face which have the co2_eq_emissions metadata field. The directory page displays each model, and shows data based on the specification outlined in Hugging Face’s documentation for “Displaying carbon emissions for your model“.
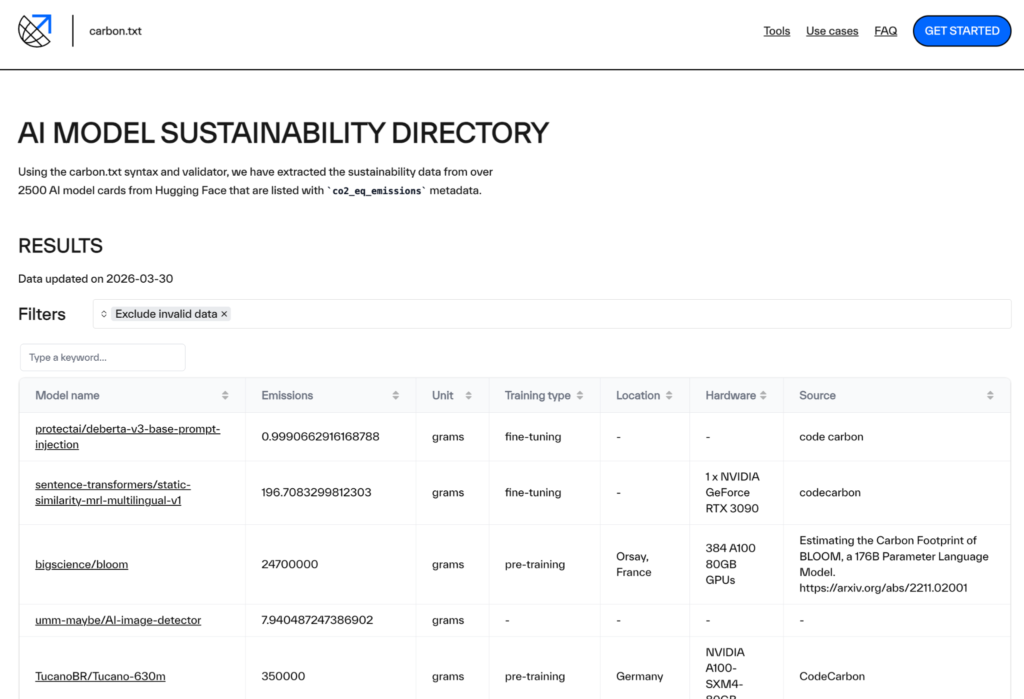
The directory can be filtered to exclude models that have missing or incorrectly formatted data. Other filters include training type, and the inclusion of training location, hardware information, and calculation source. A search field also makes it easier to look up a specific model or family of models. Through building this directory, we have found there are a large number of models that only list the carbon emissions of their training runs. These filters allow users of the directory to quickly identify those models which have declared specific data points, enabling them to make more informed decisions about the models they select.
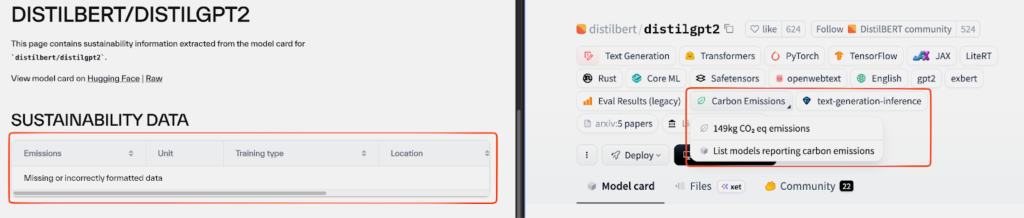
Important note: Our carbon.txt AI model card parser looks for co2_eq_emissions metadata that is structured in the format specified in the Hugging Face documentation linked above. We have noticed that a number of model cards (around 650) have not formatted data in this way. On the Hugging Face website, these model cards still display an emissions number despite not following the specification. In the Directory we have built, these models are shown with a “Missing or incorrectly formatted data” error. We plan to reach out to Hugging Face regarding this.
Model pages
Each model also has its own page, which includes links to the model card on Hugging Face as well as the raw README.md markdown file. Sustainability data extracted from the model card metadata is also presented. For example, here is the model page for the bigscience/bloom model.
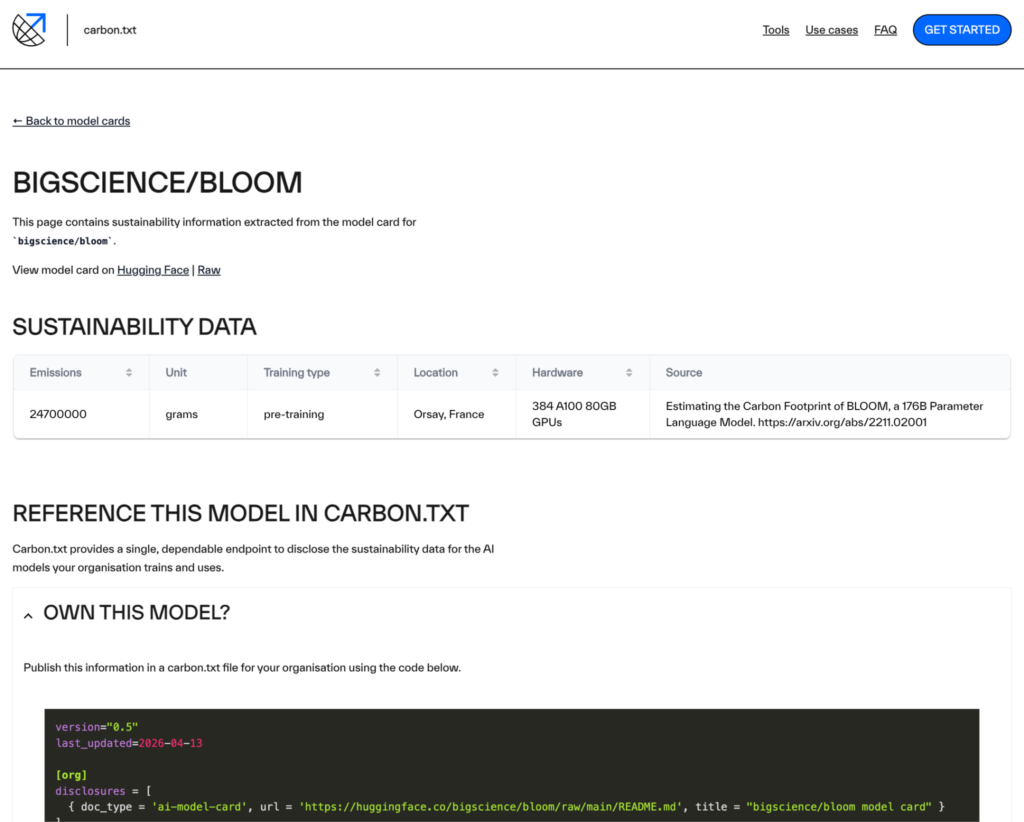
The page also includes code snippets for referencing the model in your own carbon.txt file. Currently, we only show the syntax for organisations training models. Once we have settled on a syntax to disclose model use we will add that here too. We hope that this can make it easier for folks to start sharing this information in transparent, publicly accessible formats like carbon.txt.
What’s next
The AI Model Sustainability Directory is still in beta, and we want to see what the community makes of it. You can let us know your feedback and ideas via GitHub or through our Support Form.
The 2500 models with co2_eq_emissions metadata make up just 0.09% of all models on Hugging Face. That’s a number which we hope to see increase in the coming years, and we’d love to work with the team at Hugging Face towards this. We also believe more data points should be added to the co2_eq_emissions metadata to capture additional meaningful information like training duration and eventually other metrics such as energy and water use. Having some kind of scoring system is something we’d also like to add to the directory too, as is extending it to show information beyond training data.
We’d love to see this directory grow and evolve. If you would like to support further work on the AI Model Sustainability Directory, get in touch with us about supporting our work. We also help organisations audit their technology stacks, estimate the impacts of their digital estates, better understand the environmental impacts of AI as they relate to their organisation. If these are things you’d like help with, drop us a line.

