Introduction
This briefing summarises the first phase of our carbon.txt project, funded by NGI Search. This phase has been a research and scoping phase, intended to inform the technical extension of our carbon.txt pilot. Here we describe the planned technical architecture of the open-source carbon.txt validator that we’ll build for our next phase between Oct 2024 and Jan 2025. We also detail how we plan to incorporate this new validator into our own platform for our subsequent milestone Feb 2025 – project end in April 2025.
Report contents
To navigate around this report, you can expand and contract the table of contents by pressing the + or – symbol on the right.
Executive Summary
Situation – where we are now?
Historically claims around green energy have been inconsistently and poorly defined. Evidence to back claims is often in documents that need highly knowledgable people to manually review them to understand the claims being made, and their truth. This is not just a problem unique to green energy, it is also relevant to any kind of sustainability claim.
Since the late 2000s, Green Web Foundation has tracked the transition of the internet away from fossil fuels through verifying green energy claims from hosting companies and sharing those inside the Green Web Dataset. We’ve done this using a combination of tracking IP ranges associated with organisations and manually reviewing the evidence they share with us to substantiate claims about running on green energy.
Our approach for verifying these green energy has not changed since we started, but the field around us is maturing. For example through the introduction of new legislation, reporting standards and a greater desire to tackle sustainability at a systemic level. This is creating new opportunities to build a wider sustainability data eco-system that we and the whole public space can benefit from.
But the snag is that whilst legislation is making crucial sustainability data structured, comparable and standardised, it is not making it very discoverable for others outside of government departments.
In 2023 we created a pilot of our idea, carbon.txt, which aims to take advantage of these opportunities and address this problem.
Carbon.txt is our open-source project to make sustainability information easier to discover and use. For example, a user could visit domain.com/carbon.txt to find sustainability data about that company.
Via carbon.txt we propose a standardised, yet distributed place on website domains, to efficiently surface structured sustainability data. Our dream is that carbon.txt becomes a single place to look on any domain for public sustainability data relating to that company. This would allow anyone with the technical skills to access that data and use it.
This NGI Search funded project is about taking carbon.txt to the next level so we build on these opportunities through extending our existing carbon.txt pilot.
Recommendation – what should we do?
Our plan is to extend on our existing carbon.txt convention to support processing the new kinds of data made available by changes in the law. We plan to start with the standardised reports that are mandated in Europe by the Corporate Sustainability Reporting Directive (CSRD), and the data required by the Energy Efficiency Directive (EED).
We will create a standalone carbon.txt package that we and others can use to discover and fetch CSRD and EED data presented in a carbon.txt file. We call this the carbon.txt validator. This will be the next phase of our project running Oct – Jan 2025.
Following that we intend to put this validator into use directly in our own Green Web verification process. This approach will help drive the adoption of carbon.txt as a convention for linking to publicly available structured data about companies. We’ll use our own position to create a critical mass of adoption of companies implementing carbon.txt files on their own sites.
This becomes a springboard for others to expand on the approach and create their own data pipelines and products working with the available data and the stories it can tell. We believe carbon.txt is a ‘web-first’, ‘connect not collect‘ style approach that will benefit those with an interest in scraping structured data to use in search interfaces.
Building the “carbon.txt validator” – a standalone package to read CSRD data
Our aim is to build this validator between October 2024 and Jan 2025.
Outline of the validator’s functionality
We will to build a standalone software package that can perform the following tasks:
- Find and download carbon.txt files on a given domain eg domain.com/carbon.txt
- Parse carbon.txt files to see what types of data it signposts to
- For CSRD and EED reports, parse the structured data provided to validate it is correct and return results for consumption elsewhere
We’ll explain these in more detail before outlining the architecture.
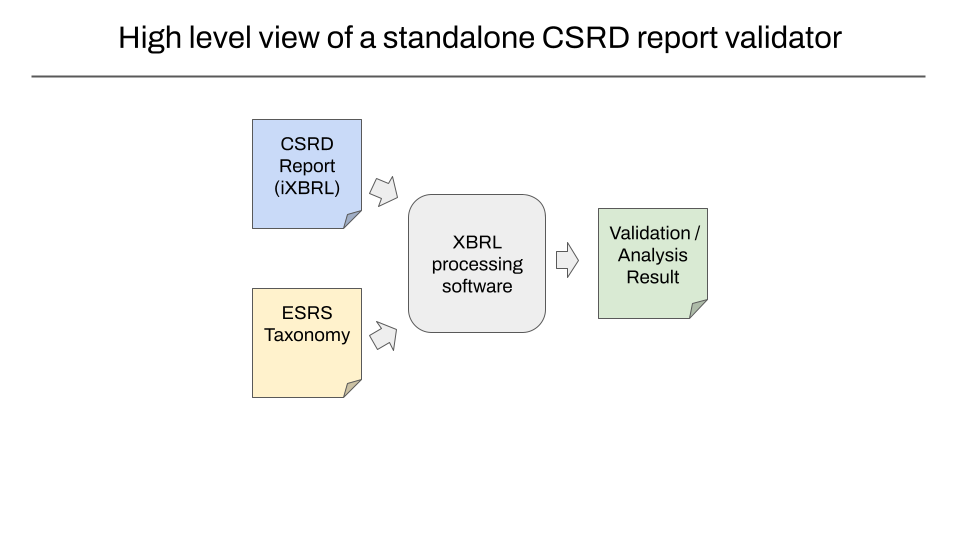
1. Finding and downloading carbon.txt files for a given domain
One key idea for carbon.txt is that given a just single website domain, it should be possible to find a valid carbon.txt file at a few predictable paths on domain. Or otherwise follow rules where responsibility for hosting the carbon.txt file is delegated to a different domain.
Our initial pilot bundled carbon.txt logic in our existing Green Web platform. This was right the decision at the time and allowed us to move quickly to prove the concept. Our first step is to extract this into a standalone library and make it open source. This is logic that ought only be written once, and lends itself well to being in a standalone library. End users would only ever need to know a domain to reliably reach a carbon.txt file they can parse for further processing.
Why a standalone validator makes sense
- A smaller and more composable project: a software package that only focuses on parsing carbon.txt files and CSRD reports is a small, focussed one. Compared to the mass of moving parts our Green Web Platform has accumulated over the years this makes it more manageable for our team to work with. It will also make it easier to onboard outside collaborators who wish to contribute, extend it or use it’s features in any data pipelines of their own.
- Demonstrating a ‘web-first’ approach for making sustainability data available to search engines: if you want sustainability data published by companies to be discoverable and easy to index, it helps to set the expectation that should be accessible on domains at a predictable place for scrapers to pick up. Our software has this assumption built into it, so we hope as more people use it and find it useful, we build a growing mass of organisations with this expectation.
2. Parse carbon.txt files to see what types of data it signposts to
A second key idea is that carbon.txt files should be able to link to different types of sustainabilty data. Primarly this is used as supporting evidence for green energy claims.
At present some of this logic exists with the platform and will also be extracted into the stand alone package. We will extend this so a carbon.txt validator accepts a CSRD and EED document type. This will include creating instructions about what they should look like and how to use them.
3. For CSRD and EED reports, parse the structured data
Now the standalone validator knows about CSRD and EED data from declarations in the carbon.txt file, the next step is to retrieve the data and check it is in a valid structure. The output is a validate data object that is ready for further processing, such as extracting specific data points.
As an example, CSRD reports are in the iXBRL format. This part includes parsing the actual iXBRL files to ensure they are in a valid structured format and returning a machine readable data format. This is most likely to be a python data object.
Understanding the planned architecture
The diagrams below use the C4 model1 for visualising software architecture, providing progressively more detail for explaining how a service or piece of software works.
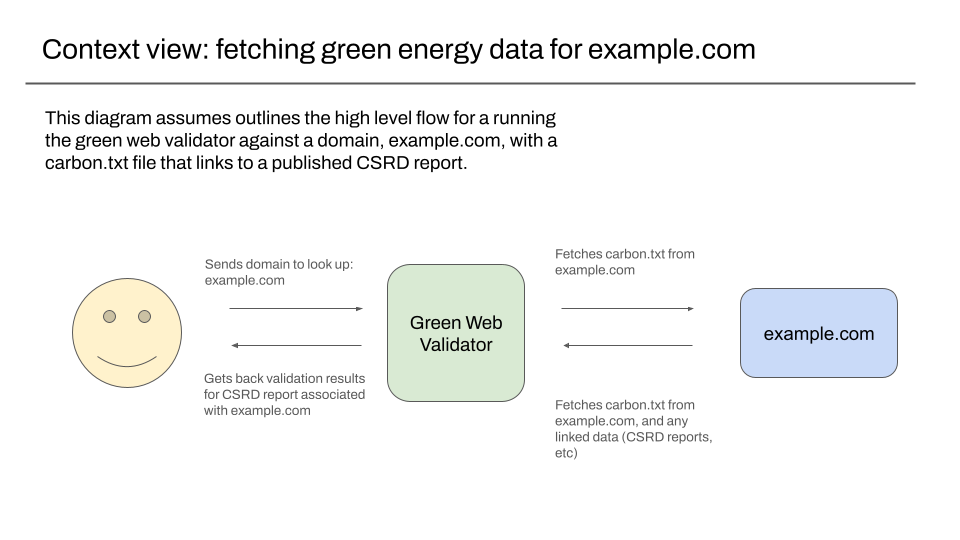
Context view – fetching green energy data for a domain
The context view is aimed at non-technical users, to explain at a very high level what a piece of software does. In our case given a specific domain, we want to be able to return the validation results for a CSRD report linked in a carbon.txt file for it.
This is how we would use the validator ourselves. It is also how we might expect others to run the same checks as us, to independently verify how our green checks might work.
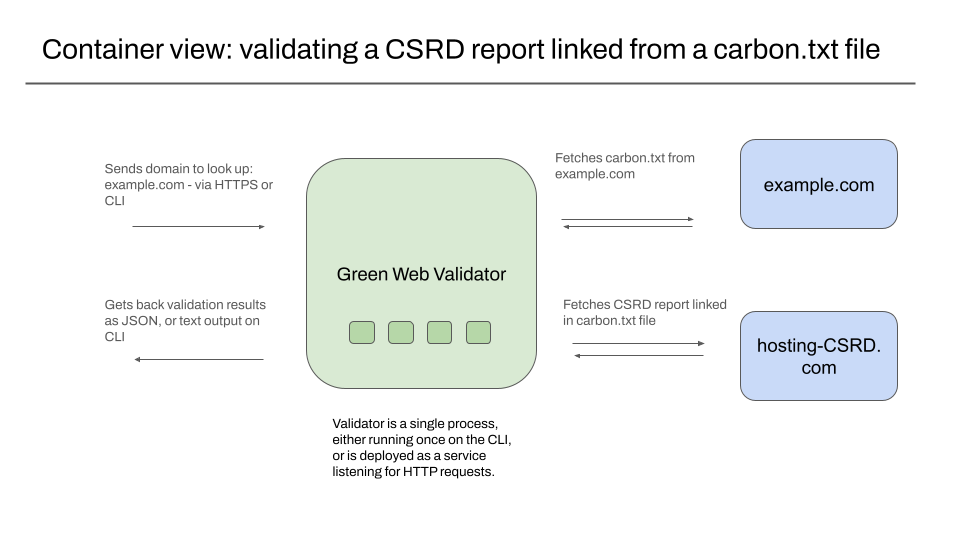
Container view – validating a CSRD report liked from a carbon.txt file
The container view provides detail about how the software is deployed or used directly, and what other services or websites it connects to. In our case, this shows our standalone validator reading a carbon.txt file for a domain, then fetching a linked CSRD report from the location listed in the carbon.txt file.
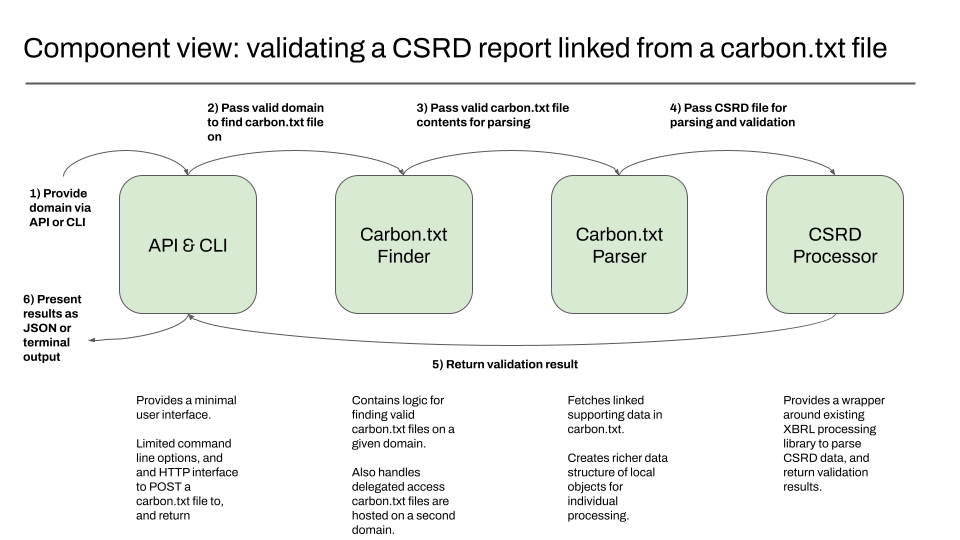
Component view – validating the carbon.txt file containing CSRD report
The component view acts as a zoomed-in view for a specific container we want to focus on. The diagram below shows the component view of the Green Web Validator container, and what specific components in the project do.
In this case responsibility is split between different components, and how we expect data to flow back out.
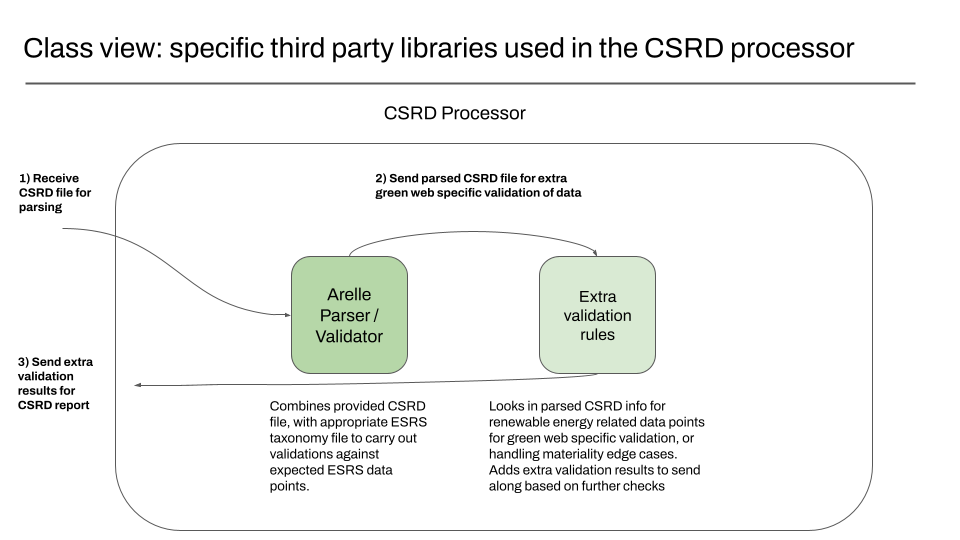
Class view: a deeper look into the CSRD processor
The class view provides extra detail about specific components in use, like specific open source libraries.
In our case, after looking over the options for working with CSRD files, the XBRL project Arelle was the strongest option for using in our project, so we have explicitly listed this here.
Our extra validation logic is handled separately from Arelle’s existing code, hence the separate package.
We know from conversations with other people in the open source community that in August, it wasn’t clear yet how materiality should be handled by XBRL parsing libraries. Until we see otherwise, we assume this is something we’ll need to handle in our own logic.
Supporting non-green web validation and parsing
One reason for having a standalone validator is to make it easier for others to build upon shared functionality for parsing carbon.txt and CSRD files, to allow new kinds of validation or processing of data coming into the public domain.
While this won’t be the focus of the initial release, the CSRD processor component would be a reasonable place to extend the project to support use outside the Green Web Foundation.
Making the validator available for download and modification
We also need to make the standalone validator publicly available for others to use. There are three main mechanisms we will support at first for easier adoption:
Github
Almost all of our technical development on our own projects happens on github, in open source repositories. A happy side effect is that our code is easy to consume in data pipelines or when deploying into live systems, because many deployment tools support public git repositories.
The Python Package Index – PyPi
In addition to developing in the open and hosting it on github repositories, we will publish the project to PyPi, the Python Package Index, and by far the most python package repository online.
As a OCI compliant container / docker image
Finally, we use a public container registry for some projects we run as containers ourselves. We will publish a minimal docker container based on the official python docker image, containing the validator. This will allow use in systems that natively support docker based tooling and OCI compliant / docker images.
Using the open source standalone validator in our own platform
Once we have built the carbon.txt validator, our next step in the project will be to make use of it in our own Green Web Platform. This phase is scheduled to take place between Feb and April 2025.
This is a deliberate strategy to drive adoption of this convention using the relationships we have with around 300 hosting providers.
For this to make sense, we firstly provide context for how our own verification process works. We also describe the details of the format used by CSRD reports, that the data comes with a degree of third party assurance, and how we could download and process them using a standalone validator. Then we outline how we will use the standalone validator in our own set of deployed applications that make up our platform and how we expect our verification processes to be effected.
Setting the scene – how we verify providers in 2024
Since the late 2000’s, the Green Web Foundation has tracked the transition of the internet away from fossil fuels. To do this we have maintained dataset consisting of:
- The domains we check
- The IP ranges containing the IP addresses that these domains resolve to
- Information about the digital infrastructure (i.e. datacentres) making websites and applications available at these ip addresses – specifically how the energy is sourced
Providers using green energy to power their infrastructure register with us. They do this so we can validate that:
- They have supporting evidence to substantiate their claims about sourcing the energy from clean, non-fossil sources
- They have a usable set of ip addresses we can use to identify websites or services as being operated by them
We then verify that:
- This evidence meets the criteria we publish for counting energy as green, and that
- There are no conflicting claims about control over these ip addresses
The criteria we use for verifying claims about green energy broadly follow the guidelines published by the GHG Protocol on Scope 2 emissions. Our staff use these criteria when we make manual reviews of the evidence provided, in order to make a judgement about whether the evidence supports a claim about decarbonising electricity.
Our platform’s software contains internal rules to resolve conflicts about who ip addresses are allocated to, so that when a domain is looked up, we can trace it to the correct provider.
How this is used in search services now
We make the ability to check a domain available in our primary “green web check” service on our main website, available via an API. We also regularly publish open datasets of the domains we have marked as ‘green’, with our green domains dataset. Existing tools consume this data, and either use it as a factor in to either filtering or annotate search engine results.
Green Web results in search with the Green Web browser extension
Launched in 2010’s, the Green Web browser extension uses our API to check domains as they visited in a browser, or as they show up in search engines, by modifying the HTML that a user’s browser renders on screen.
If a site shows up as green, the result is annotated with a green badge, and in the absence of information, results are shown a default ‘grey’ annotation. The screenshot below shows an example annotated listing result:
Use in on the server in Searx / SearXNG
Our API results are also used in other software Our datasets are also used in the open source meta-searx engine Searx, and its successor, SearxNG. Meta-search engines like searx work by sending requests to various existing search engines, via a proxy to protect a user’s privacy.
This proxying function of metasearch engines does more than just stop user data being sent along to search engines – it also works the other way, allowing users to control the results they see. Our dataset is used for filtering results to only show ones running on infrastructure powered by green energy2.
Meta search engines can be installed for personal use, but sites like searx.space exist to list open instances for anyone to use for private searching3.
Other uses
We publish our datasets as open data, without any requirements to sign up before accessing them. The same applies to our API usage, so we often first find out about novel uses of our data when new products are launched using it, or when developers ask for guidance on how to use our data during implementation.
How this verification has changed historically, and it can change in future
This verification process was originally designed more than 10 years ago. As the number of providers we verify increases each year, so has the amount of time needed to verify them in total.
We have made changes to make uploading data easier, and to keep providers better informed during the verification process, but fundamentally the approach has been the same, based around manual review.
Changes ahead in reporting sustainability related data
However we have seen a raft of new laws, and new standards develop over the last few years – in particular about how companies report the steps they take to decarbonise their operations.
In Europe, there is now a veritable alphabet soup of overlapping laws that are leading to greater disclosure by companies about their own carbon emissions, but also the emissions in their supply chain. Laws like the EED (energy efficiency directive) CSRD (the corporate Sustainability Reporting directive), and the CSDDD (Corporate supply chain due diligence directive), all provide an impetus to share data that hasn’t been shared before, and the Green Claims Directive, is driving companies to provide clearer, substantiated standardised sustainability claims too.
In the USA, the CCDAA (Climate Corporate Data Accountability Act) is setting a precedent for state-level reporting, and the SEC (Securities and Exchange Commission) is also mandating climate disclosure for investors.
Other regions like Australia, Singapore, and India all have related legislation, much of which has been designed along the same kinds of international reporting standards as the laws in Europe and the USA.
Changes in linking domains to organisations and their infrastructure
Similarly, we have seen new approaches online for verifying whose servers we really connect to, when we visit a domain like mycompany.com, which are used for establishing safe and secure connections.
The flagship example is the Internet Security Research Group (ISRG)’s project LetsEncrypt, and the ACME protocol it uses for domain validation, as part of the process for issuing a certificate to use for connecting via HTTPS.
Around 2016, around 40% of the web was accessed using more secure HTTPS connections4. By 2020, LetsEncrypt had issued one billion certificates using this domain process, leading to 81% of the web globally being accessed over HTTPS rather than HTTP5.
These approaches do not rely on IP addresses, but use domains directly, and rely on an organisation claiming responsibility for a domain being able to demonstrate control over it the domain, to establish the link between the domain and the organisation.
In the next sections we provide a summary of the developments in legislation that may affect how we validate that providers are sharing information with us. We’ll then do the same for covering some of the new options for verification available to us.
Updating our verification flow to use carbon txt
Supporting the different scenarios for companies getting validated
There are three main scenarios with three specific claims we intend to support.
- Scenario one: We use green energy for all the energy we use, and we operate our own data centres
- Scenario two: We use green energy for the digital infrastructure, and we operate our own data centres
- Scenario three: we only use datacentres from companies who themselves use green energy for all their energy use, and operate their own data centres
Scenario one: We use green energy for all the energy we use, and we operate our own data centres

The first scenario is the one that is directly supported in the ESRS data, and has a data point we can directly reference in a published report. This is data that carries a degree of assurance, which reduces the requirement for verification via other supporting evidence.
Our validator would be able demonstrate that this data exists in a report, and is in the form we look for.
When providers register with us, we require a staff member to act as a point of contact – for annual re-verification and for answering any further queries.
Assuming we have contact details for this member of staff, and have verified someone is still reachable at those contact details, a valid carbon.txt file, linking to a valid CSRD report would be sufficient.
Scenario two: We use green energy for the digital infrastructure, and we operate our own data centres

As mentioned before, we can not rely on the data in the CSRD report alone for companies that a) use green energy for digital infrastructure, but b) do not use green energy for the rest of their operations.
Having the link established is helpful for other queries that other consumers of CSRD data might have. However, because there is no real concept of digital infrastructure in the data points in the ESRS defined, we would need an alternative mechanism for making this claim, as well as sharing supporting evidence.
Our existing verification flow would not need to change that much in this scenario. Having the link to a published CSRD report in a carbon.txt file for is still something useful for enabling a wider ecosystem to consume linked data, but it would not directly influence our own verification of the green claim we verify.
Scenario three: we only use datacentres from companies who themselves use green energy for all their energy use, and operate their own data centres
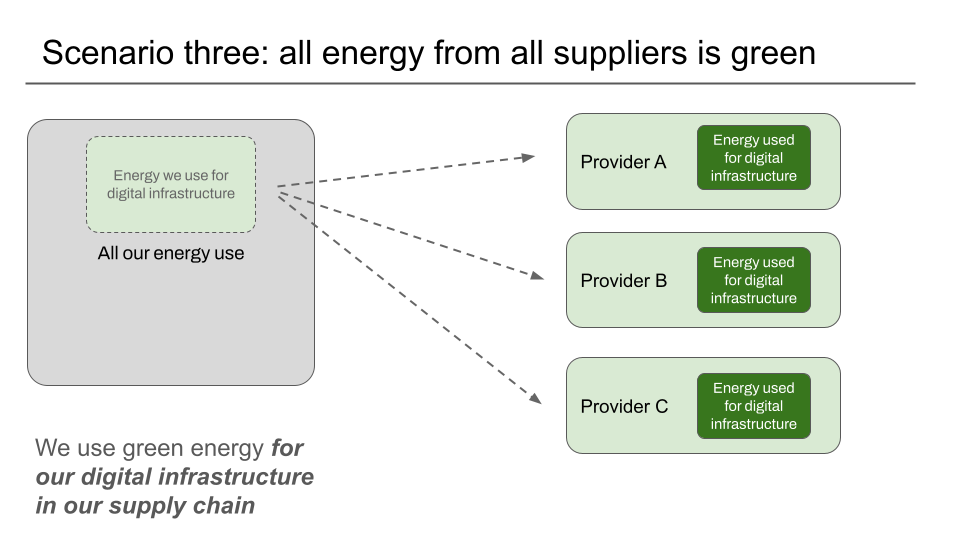
Where a provider does not operate any data centres themselves, and exclusively uses third party providers of infrastructure who themselves have published CSRD reports making the same all green energy, all our own data centres claim as in scenario one, validating a carbon.txt file would be able to tell us that the upstream providers would count as green, as long as there was some supporting evidence that they were customers of the infrastructure.
We currently rely on a manual process of sharing redacted invoices and or similar for this scenario – to establish the link back from the suppliers to the provider trying to be verified.
How our deployment setup changes
Running a standalone provider will change our default deployment set up for the green web platform. The diagrams below describe the changes to implement.
Our current setup – parsing, validation, and linking to providers happens in the platform
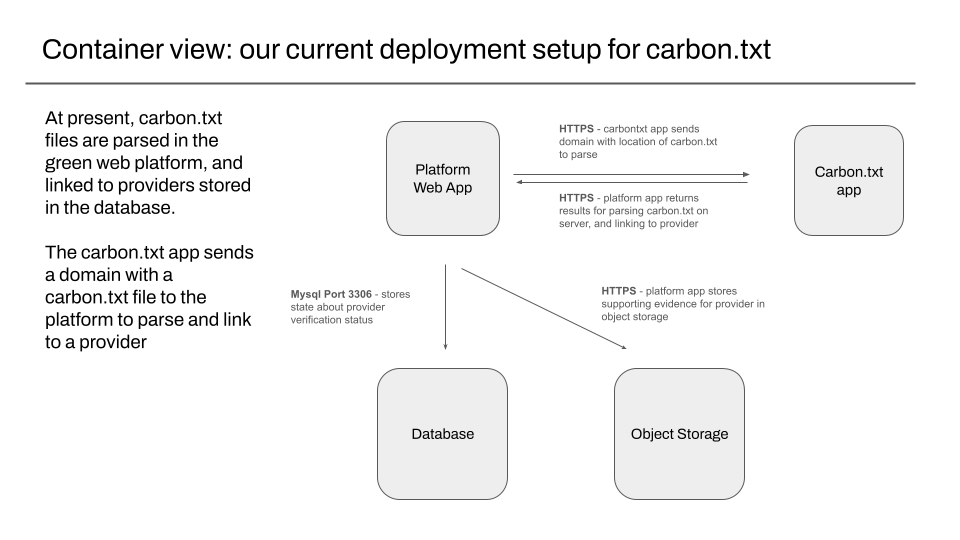
With our current setup, all the code for fetching and parsing carbon.txt files is in a series of modules in the existing platform web app , that we maintain on github.
Our public facing site explaining carbon.txt, at https://carbontxt.org is a mostly static site, that sends API requests to the same web app servers that serve the rest of the green web check traffic we serve each day.
The same platform web app is responsible for storing the results of parsing a carbon.txt file for an existing hosting provider in our relational database , and for fetching and storing a copy of any supporting evidence linked in the carbon.txt file, for later reference.
This evidence is stored in object storage, which provides durable, redundant storage of uploaded files. Public evidence in object storage is accessible without authentication, but private evidence is only accessible via requests routed through the platform web app, and its permission system.
The new setup: a standalone validator deployed separately.
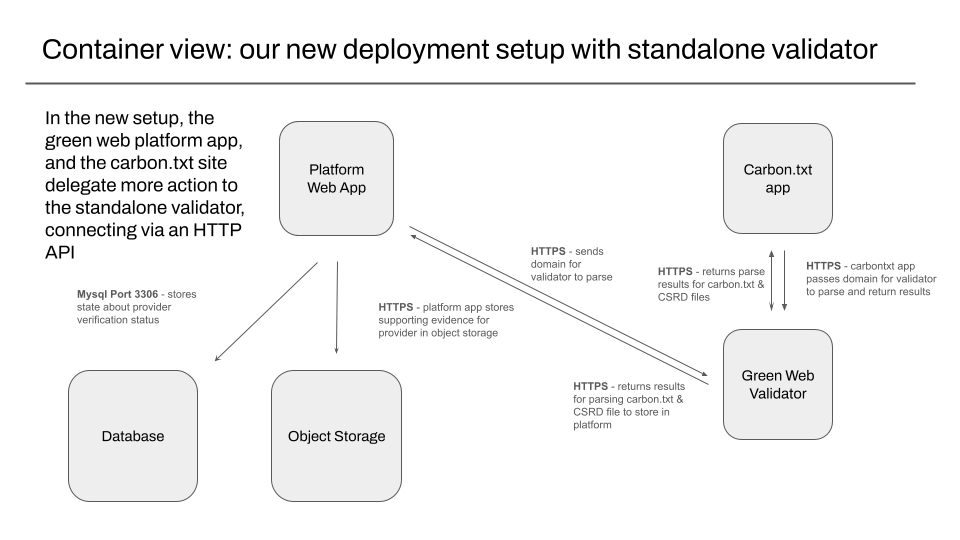
With the new setup, all the code for fetching and parsing carbon.txt files is now extracted into the standalone validator, which can be deployed independently of the existing django web app.
The standalone validator is responsible for making sure carbon.txt files are valid, contain usable links, and the linked data is itself valid and well formed. The platform web app is still responsible for verification, and linking this carbon.txt file with evidence to a provider in the database .
The platform web app is still also responsible for using this stored evidence to show a green result. The platform web app is also responsible for storing when this check took place – we use this for our audit trail, but also to have a single place to record checks, for later analysis.
The platform web app is still responsible for storing copies of any evidence linked in carbon.txt files, in object storage.
Summarising verification with carbon.txt extracted into a standalone package
The functionality we initially implemented for parsing carbon.txt files was built inside our main django web application out of convenience. However much of this logic is reusable outside the main web app, and would be useful for others who might also use carbon.txt files to process the kinds of publicly accessible structured data in CSRD reports that will be published in the coming months.
Extracting the logic into a standalone package would add some extra complexity to the way we deploy our platform, as we would have a single extra application to deploy. The upside would be a clearer separation of responsibilities within our platform – so by demonstrating how we consume the output of the validator, it becomes clearer how we expect carbon.txt to help with the process of discovering and using published, structured, data about company social and environmental records.
Additional research around validation
For the purposes of this document, we use the term validation to describe the act of making sure that data exists, and is in the form we expect it to be such that we can understand it, and process the data in some meaningful way.
In our case, this usually involves assessing the claims made by the data shared with us, so we can make a decision about showing a provider as ‘green’ in our checks. We refer to the assessing the claims as verification, and treat them as separate from validation.
What are we looking for when we are validating data shared with us?
There are two kinds of data we validate right now: data about energy and decarbonisation, and data about what we refer to as a provider’s network footprint (the internet address space we might see as a provider being responsible for).
Validating energy and decarbonisation
For validating energy data there are a few questions we need to answer about the document, including but not limited to:
- Is it referring to the correct organisation?
- Is it referring to the correct time period?
- Is it referring to energy or carbon emissions using the units and values we expect?
- Is there any information about the document’s provenance we can rely on for assessment later?
Validating network footprint
For validating the network footprint, we have a different set of questions including:
- Is this referring to the correct organisation?
- Is it referring to the correct time period?
- Is the network information in a form we can use in our platform?
- Is there information about the provenance of any supporting documentation provided?
How do we validate that information is in the form we need at present?
| Question | Applicable to: | What evidence we require | How we validate the data | Notes |
| Is it referring to the correct organisation? | Carbon emission / EnergyAnd Network footprint | Evidence that the submitter is working for the organisation, or is allowed to represent the organisation. | We explicitly ask in our submission forms, and manually check email domains of people making submissions for a company | |
| Is it referring to the correct time period? | Carbon emission / EnergyAnd Network footprint | A clear start and end date for when this data is considered valid | We require this in our wizard, and manually check uploaded documents. | Data needs to be re-verified each year by providers. Providers who do not reverify are archived until new evidence is provided. |
| Is it referring to energy or carbon emissions using the units and values we expect? | Carbon emission / Energy only | All energy use is matched on an annual basis with certificates, or the carbon emissions have a matching amount of carbon removal | We require either absolute numbers to balance out if the organisation isn’t using 100% matched energy tariff. We manually check the uploaded data against our own published criteria for accepting as evidence of green power. | |
| Is there any information about the document’s provenance we can rely on for assessment? | Carbon emission / EnergyAnd Network footprint | A clear external organisation or issuing body we can investigate further if needed for invoices or certificates. In the case of a report issued by the organisation itself, we look for Independent assurance by a competent auditor. | Varies based on the kind of evidence, but includes manually checking the existence of the organisation, and that invoices or certificates contain the information we expect (amounts, the correct named organisation, and so on) | |
| Is the network information in a form we can use in our platform? | Network footprint only | IP Ranges, or exclusively allocated Autonomous System Numbers (ASNs) | Our submission forms explicitly validate that IP ranges are well formed that our platform can process and that ASNs refer to real Autonomous Systems |
What new options exist for validating data shared with us that didn’t before?
One of the goals of carbon.txt is to take new data that will be published in the public domain, and make it more discoverable, enabling new and innovative uses of the data – particularly for search engines or other lookup services like the ones we offer.
However, it’s clearer to separate out validating carbon / emissions data first, before looking at how we validate network footprint data. We’ll focus on carbon / emissions data which is most affected by changes in the law, before looking at network footprint data.
Looking at carbon / energy data – what are these new laws mandating disclosure?
The key law we are aiming to take advantage in Europe is the Corporate Sustainability Reporting Directive6 (the CSRD), a law that mandates an unprecedented degree of disclosure for affected companies operating in Europe. Companies do not need to be European to be affected by the CSRD – as long as they operate in Europe and meet the criteria around revenue, sheet balance size or employee headcount7.
Companies affected by the CSRD are legally required to provide a set of disclosures along as outlined in the diagram below8. In addition to general requirements like when and where the company was incorporated, there are now a set of standardised disclosures that refer to climate change, biodiversity and ecosystems, resource usage and so on, using established Environmental, Social and Governance groupings.
Also, these reports require explicit (limited) assurance of their content by qualified third parties, meaning organisations can’t just self report.
There are other laws in Europe that support the CSRD, along with laws outside of Europe that are complementary.
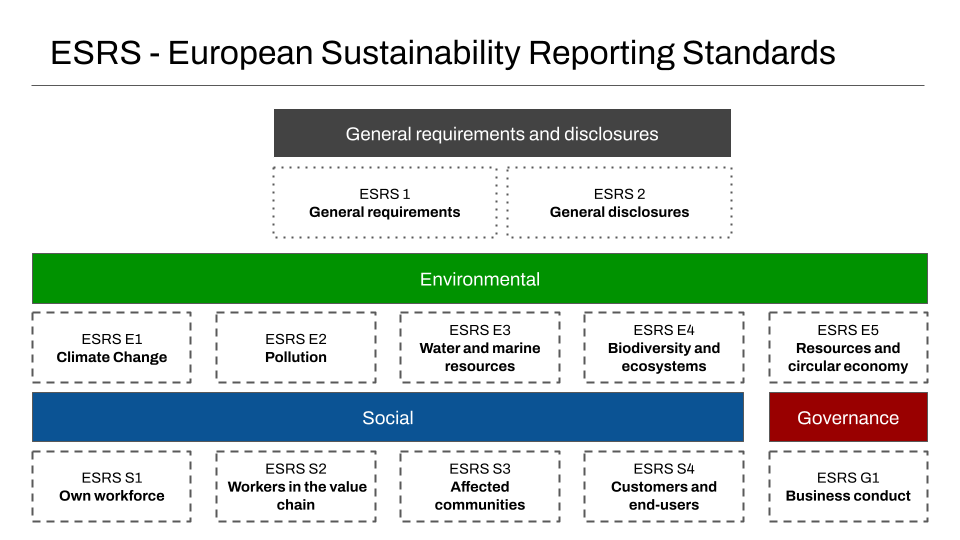
Standardised reporting
The expected form of each type of disclosure, is detailed following the European Sustainability Reporting Standards (ESRS). These explicitly set out a set of numbered standards for how data should be collected and reported. These are also grouped by theme, including:
- Environmental (ESRS E1 Climate Change, ESRS E2 Pollution, ESRS E3 Water and marine resources, ESRS E4 Biodiversity and ecosystems, and ESRS E5 Resources and circular Economy)
- Social (ESRS S2 Own workforce, ESRS S2 Workers in Value Chain, ESRS S3 Affected communities, and ESRS S4 Customers and End Users), and
- Governance (ESRS G1 Business Conduct)
Standardised Units
Each numbered ESRS Standard, (i.e. ESRS E1 – Climate Change), contains a specific set of detailed disclosure requirements (DRs), which also detail the units to use, and guidance to calculate them. The table below is an extract from a larger published excel spreadsheet that lists each set of the disclosure requirements, along with the required data type. Each named disclosure below links to further detailed information about the type of unit to use and how to calculate it.
| ESRS | DR (disclosure requirement) | Paragraph (in docs) | Disclosure Name | Data Type | Further details |
| E1 | E1-5 | 37 | Total energy consumption related to own operations | energy | Link |
| E1 | E1-5 | 37 a | Total energy consumption from fossil sources | energy | Link |
| E1 | E1-5 | 37 b | Total energy consumption from nuclear sources | energy | Link |
| E1 | E1-5 | AR 34 | Percentage of energy consumption from nuclear sources in total energy consumption | percent | Link |
| E1 | E1-5 | 37 c | Total energy consumption from renewable sources | energy | Link |
| E1 | E1-5 | 37 c i | Fuel consumption from renewable sources | energy | Link |
| E1 | E1-5 | 37 c ii | Consumption of purchased or acquired electricity, heat, steam, and cooling from renewable sources | energy | Link |
| E1 | E1-5 | 37 c iii | Consumption of self-generated non-fuel renewable energy | energy | Link |
| E1 | E1-5 | AR 34 | Percentage of renewable sources in total energy consumption | percent | Link |
How do we validate that reporting follows this format?
In Europe the CSRD explicitly states that the new annual reporting covering the topics above must be published on company websites:
Member States should be able to require that undertakings subject to the sustainability reporting requirements of Directive 2013/34/EU make their management reports available on their websites, free of charge to the public9.
We have seen that it mandates specific data points to include, and specific types or data to report. One goal of the data is for it to be machine-readable as well, so a specific file format is required for this data – The European Single Electronic Reporting Format10.
Understanding the the ESEF – a dialect of XML, incorporating ideas from XBRL and XHTML
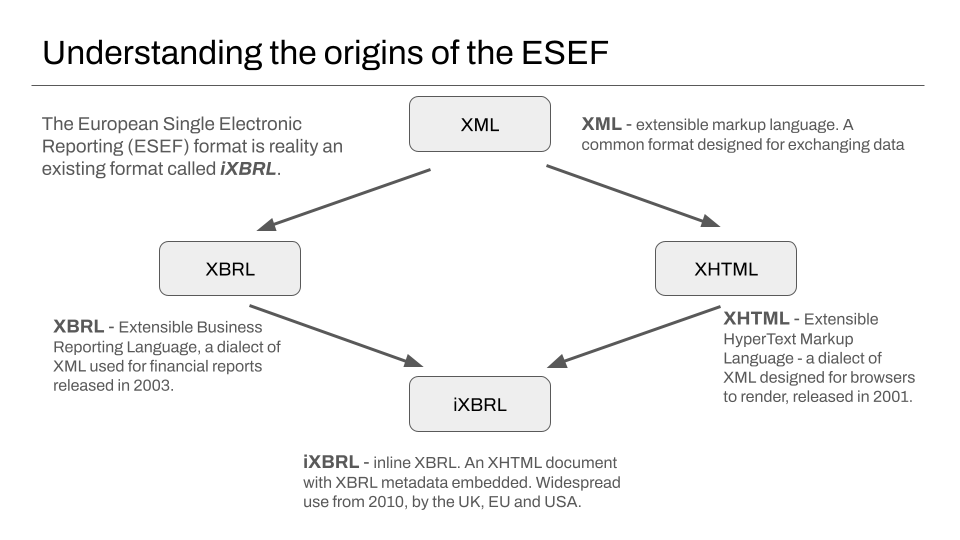
If the idea of supporting an entirely new file format for a new law sounds daunting, it’s helpful to know that the ESEF is really a format that has seen widespread use since 2010, which itself is based on mature technology that has been in use for more than twenty years.
The underlying ESEF file format is iXBRL, a variant of the commonly used XHTML file format supported by almost every modern browser since the mid 2000’s, that incorporates some of the extra markup from XBRL, a variant of XML that has been in use in reporting for a similar period.
Because the format is a variant of XML, a very healthy ecosystem of battle-tested open source validation software already exists. Also, because of the ESEF’s origins in XBRL, it supports an already-established way to validate the correctness of a report against different standards – using specialised taxonomy documents11.
These laws and established technologies work together to provide a new way to validate information for specific providers. The requirement of limited third party assurance allows for validating the provenance of information, as well as helping with verification, the second activity.
Ecosystem support for creating and parsing reports that can be digitally validated
The CSRD has been a long time coming, and the fact that it is mandatory for companies above a certain size has been a boon for the ESG reporting industry. At least 50,000 companies in the Europe will need to publish structured reporting to comply with the CSRD in 202412 – as well as separately requiring qualified auditors provide assurance for this reporting.
In this sector there are consultants and software-as-a-service vendors building software designed to make working with XBRL and XBRL derived reporting easier.
XBRL International, the non-profit responsible for the XBRL standards, also operates a certification process for software that it tests and guarantees to be compatible with other software passing certification. It maintains a list of software certified as Report Creation Software, Review and Consumption Software, and Validating Processors.13
Given our interest in parsing these iXBRL reports mandated by the CSRD, it’s worth seeing what software exists that we can use ourselves, to avoid starting from scratch.
One example of SaaS using open source foundations – Workiva and Arelle
While a number of open source libraries exist for working with reports, one of the higher profile providers of reporting creation software is Workiva14, who provide various compliance and reporting software tools.
Under the hood, their flagship software use Arelle15, an open source python library for working with XBRL reporting data. In addition to being used by more than 50 other companies, Arelle is also certified by XBRL as a Validating Processor, and there is an active community of contributors around in Europe and the USA maintaining Arelle.
On 30th August this year, EFRAG, the body set up by the European Commission to help with the adoption of the CSRD in business and sustainability reporting, published the first ESRS Taxonomy – a specialised taxonomy document designed to help with validating reports against the the agreed standards. Even before this was available, work in the community had begun to support validation using draft versions of the ESRS taxonomy inside Arelle16.
Arelle is not the only open source library for working with XBRL derived documents, like those required by the CSRD. However, it is well documented, carries official certification, is used by a number of firms that pay their employees to contribute back to it, and it has a versatile plugin system with various open source plugins in the public domain. It’s a good example of the established healthy ecosystem around structured reporting.
Challenges to navigate with digital validation of carbon emissions / energy data
One of the challenges related to using published CSRD data is the concept of materiality. Another is related to reporting timelines.
Materiality – will companies include the data we expect in their reporting?
While the laws mandate disclosure of detailed, structured, machine readable data by companies, not every single datapoint inside the CSRD needs to be reported by every company.
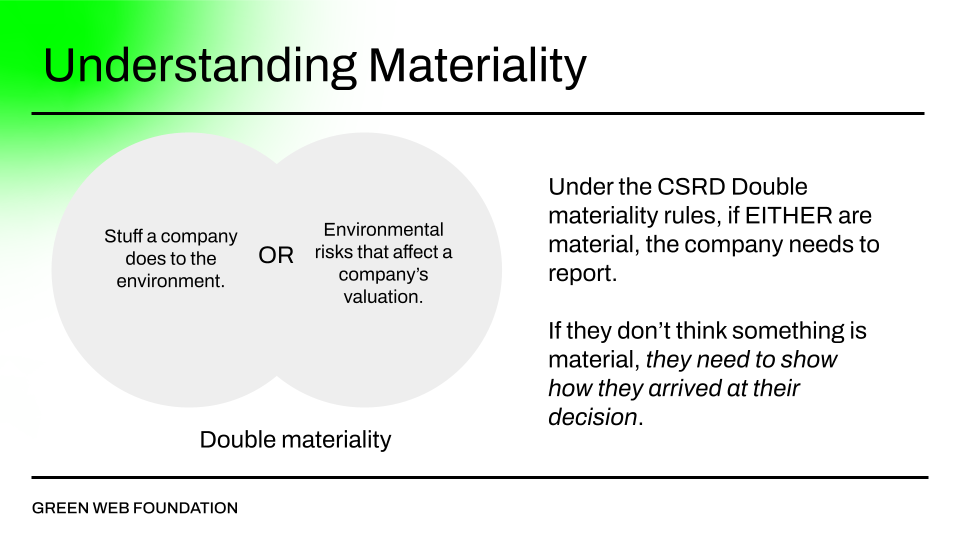
The guidance around materiality is extensive17. In short, companies need to report detailed data if a type of activity is considered financially material to an organisation (i.e. if the climate changing is likely to impact a company’s valuation), or if something has what is referred to as impact materiality (i.e. there are environmental impacts incurred by the activity on the outside world).
If the activity is not considered material, there needs to be some justification, and transparency in how an organisation worked with an auditor to arrive at the decision.
For a company that primarily operates data centres that it owns, things like energy usage are very likely to be considered material, and the CSRD documents are likely to contain useful information for validation and verification.
It is less clear cut for companies that consume significant amounts of digital services in their supply chain, but are involved in other significant activities, and the eventual decision may vary from auditor to auditor.
This may limit the kinds of organisations who might be able to provide usable data from their CSRD report for our verification, and any tooling we use to parse reports will need some understanding of materiality built into it.
We expect various sectors to come to some kind of consensus about what tends to be considered material in 2025, but for the first year at least, we will need to plan for it.
Timelines – will companies publish reports early enough for us to use?
The other consideration for relying on published CSRD data are the timelines associated with reporting, and understanding the incentives involved is helpful for our planning.

Report because it’s the law
We have established that the CSRD is mandatory, and that the first year for publishing is 2025.
In some countries like France, there not are just significant fines for not publishing the data, but there is also the prospect of jail time for directors of companies if they block disclosure18. While staying out of jail is likely to be important to company management, it doesn’t necessarily incentivise early disclosure – as long as a company disclosures that year all should be well. This is good for company directors, but less good for demonstrating the use of data in our case.
Report to help raise money
However, once you understand one of the main use cases for CSRD data for companies, incentives for early disclosure become clearer.
The key expected use of data in the CSRD is to help direct finance for green investment, as part of the wider European Green Deal, and there are two drivers:
- First of all in Europe investment funds are responsible for ensuring that the companies in their portfolio have published CSRD reports, and must be able to produce them when asked by a regulator
- Secondly, the data in the reports is intended to help investors make more informed decisions about the climate risk associated with making investments, and to help them decarbonise the portfolios they hold
Having published reports as a prerequisite for accessing funding would likely incentivise companies trying to raise capital for their operations, but various forms of government support and subsidies also exist for green finance.
This means that the earlier companies publish CSRD reports for external parties to use, the sooner they are able to access green finance at favourable terms – assuming their activities are sufficiently ‘green’ for their investors.
Summary for validating carbon emissions / energy data
| Question | What evidence we require | How we validate the data | Notes |
| Is it referring to the correct organisation? | Evidence that the submitter is working for the organisation, or is allowed to represent the organisation. | We explicitly ask in our submission forms, and manually check email domains of people making submissions for a company. If we do not use the wizard, companies are mandated to publish reports on their own website, allowing for staff to check. | |
| Is it referring to the correct time period? | A clear start and end date for when this data is considered valid | We require this in our wizard, but the linked CSRD reports have explicit validity periods we can refer to as well. | |
| Is it referring to energy or carbon emissions using the units and values we expect? | All energy use is matched on an annual basis with certificates, or the carbon emissions have a matching amount of carbon removal | For companies running entirely on green energy, the disclosure requirements for ESRS E1 require the same information we do. | |
| Is there any information about the document’s provenance we can rely on for assessment? | A clear external organisation or issuing body we can investigate further if needed for invoices or certificates. In the case of a report issued by the organisation itself, we look for Independent assurance by a competent auditor. | The CSRD requires an organisation to publish reports that have had third-party assurance. They also need to disclose the extent that this follows existing standards from bodies like ISO and CENELE (international standards groups). We already rely on this assurance, but look for it manually. |
Looking at network footprint data – what changes are we able to use?
To understand what changes are available, it helps to understand how our system links a domain to an organisation at present first, before we look at how domain-based approaches like carbon.txt work.
How we validate domains at present
When we look up a domain, we consult DNS records that eventually resolve to an IP address that a server is reachable at. In our database we associate IP addresses with a given organisation three different ways outlined in the diagram below – by IP address, by IP Range, or by Autonomous System Number (ASN)
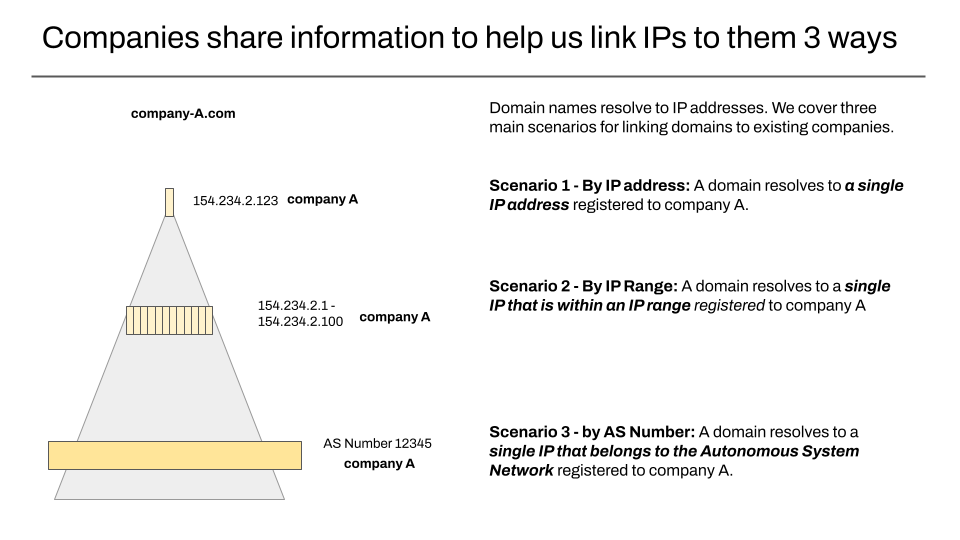
For the most part, we are relying on information stored in DNS records added by an organisation that has the control over a domain, and then we are checking that against information previously shared with us.
So, when someone runs a green web check against a given domain, we base the ‘green’ / ‘not green’ result on our ability to link a domain to an IP address shared with us.
If the organisation associated with that IP address has shared the necessary sustainability data with us, then we can establish a link between the domain and the organisation’s sustainability info allowing us to serve a ‘green’ result.
How does a domain-based approach work for understanding an organisation’s network footprint?
Both carbon.txt and the ACME Protocol behind LetsEncrypt work on domains rather than IP addresses, and both rely on being able to demonstrate control over a domain, as the basis for sharing a positive result.
For carbon.txt, and our green web checks, a positive result is showing a ‘green’ via our API, or website.
For the ACME protocol, a positive result involves a certificate being shared to the server demonstrating control over the domain. The server is then able to use this certificate for secure connections over HTTPS.
Expanding the number of domains showing as green for an organisation
In both cases, it is possible to link new domains via an automated process to an existing organisation – this is what has allowed LetsEncrypt scale support to over 450 million domains19.
In our case, an organisation previously expanded its registered network footprint with us by sharing more IP addresses with us. These are the IP addresses that domains it hosts would resolve to. With the domain based approach, it directly registers domains via an API.
In both carbon.txt and the ACME protocol, demonstrating control over the domain is important, and there are various security measures to protect against bad actors trying to get SSL certificates issued when they shouldn’t, or companies trying to get domains marked as green when they shouldn’t.
We won’t go into how carbon.txt20 and the ACME Protocol21 protect against bad actors trying to claim ownership of a domain – this is covered in detail on the external sites linked in the endnotes.
For this document, the key details are that rather than needing to keep track of IP address data shared with us, and validating that this IP address data is in the form we need, we interact with domains directly.
We use DNS queries on a specific domain to find the location of a carbon.txt to read, which contains the information we need.
With a domain based approach we are primarily validating that the domain is:
- a) reachable, and
- b) hosting a publicly accessible carbon.txt file that contains links to information that is also publicly accessible.
A helpful side effect of this is that validating carbon.txt files and structured data in CSRD reports becomes something that can happen outside of the main Green Web platform.
Summary for validating network footprint
| Question | What evidence we require | How we validate the data | Notes |
| Is it referring to the correct organisation? | Evidence that the submitter is working for the organisation, or is allowed to represent the organisation. | We explicitly ask in our submission forms, and manually check email domains of people making submissions for a company. If we do not use the wizard, companies are mandated to publish reports on their own website. The validation of the organisation’s control over a domain is also built into the carbon.txt protocol. | The carbon.txt protocol validates that an organisation being assessed has control over the domain it wants to mark as green, following a process similar to the ACME protocol. |
| Is it referring to the correct time period? | A clear start and end date for when this data is considered valid | We require this in our wizard, but the linked CSRD reports have explicit validity periods we can refer to as well. | |
| Is there any information about the document’s provenance we can rely on for assessment? | A clear external organisation or issuing body we can investigate further if needed for invoices or certificates. | The CSRD requires an organisation to publish reports that have had third-party assurance. They also need to disclose the extent that this follows existing standards from bodies like ISO and CENELE (international standards groups). | |
| Is the network information in a form we can use in our platform? | N/A | N/A | Carbon.txt relies on domains directly, rather than indirectly with an approach based on IP addresses |
Additional research around verification
When we say verification in this context, we are referring to assessing veracity or trustworthiness of a claim made by valid data shared with us.
The key claim we aim to verify is that an organisation’s digital infrastructure is running on green energy.
More specifically, we verify that:
- this evidence meets the criteria we publish for counting energy as green, and
- there are no conflicting claims about control over these ip addresses
These can be addressed independently, and loosely correspond to:
- parsing structured data from CSRD reports that already has third party assurance, and
- design decisions built into carbon.txt to avoid conflicting claims
Verifying that there are no conflicting claims of control
If we start with the second of these, we have covered in the validation section above that a domain based approach doesn’t rely on IP addresses.
Instead, a couple of scenarios we want to avoid are:
- Using someone else’s data to look green: Company B, running company-b.com, using data hosted on company-A’s website to present itself as running on infrastructure powered by green energy
- Using data you host to make false statements about someone else: Company B, running company-b.com, making claims about company A, accessible at company-a.com.
In both cases, this is where control of a domain is important. Without going into too much detail, information in a carbon.txt by default can only apply to the domain it is already hosted on – this is somewhat like the same-origin22 policy used to secure the web since 1995.
If this was the only possible approach supported by carbon.txt, this would stop lots of valid uses, like a hosting company managing thousands of domains of websites they host, and wanting them to show green results like they do now.
For this reason, if and only if it is possible to demonstrate control over a different second domain, then it is possible to use data in a carbon.txt file hosted on one domain, to make claims about the second domain.
We offer an interactive notebook using Observable, an open source platform23 to demonstrate how this domain process of demonstrating control over a domain works24.
Verifying green energy claims
In order to verify that an organisation is making a defensible claim about running on green energy, we have one key question to answer, assuming that we have validated that the data is in the form we accept, and accessible:
- Is the company making a claim that could be supported by the data provided?
We detail what information we require for manual checks on our published guidance on the What we accept as evidence of green power page on our website25. The following section refers to verification using digital means that are now supported by new data in the public domain.
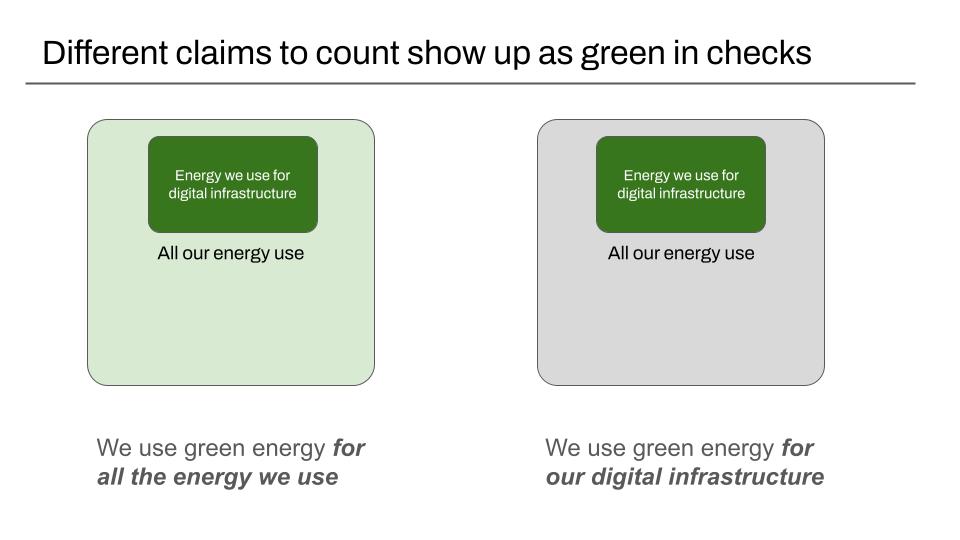
Broadly speaking, companies make two kinds of claims, that require different kinds of data
- We use green energy for all the energy we use
- All the digital infrastructure we use is powered by green energy
Claim 1: We use green energy for all the energy we use
If a company uses green energy for all its energy use, then energy for digital infrastructure it owns and operates (i.e. it is running in a data centre it owns) is a subset of this energy use – it would be covered by this statement.
There is an explicit datapoint in ESRS 1 that any parser would look for to confirm this claim – ESRS E1-5_05 – Share of renewable sources in total energy consumption (%).26
To make this more concrete, this shows up in report markup looking like the code sample below:
<span xmlns="http://www.w3.org/1999/xhtml">
<ix:nonFraction
xmlns:ix="http://www.xbrl.org/2013/inlineXBRL"
name="esrs:PercentageOfRenewableSourcesInTotalEnergyConsumption"
format="ixt4:num-dot-decimal"
decimals="2"
scale="-2">
100.00
</ix:nonFraction>
%
</span>We know that CSRD reports require independent assurance of the data published, so rather than relying on Green Web Staff to manually verify the existence of this data in evidence shared with us, we instead are relying on the data that has been published, with a third party verification already.
Blindly consuming a data point, even one with independent third party assurance might feel a step down on transparency when compared to some reports we link to. In this scenario, there are other data points we might look for, that may provide extra context. One such example is ESRS BP-2_19 – Disclosure of extent to which data and processes that are used for sustainability reporting purposes have been verified by external assurance provider and found to conform to corresponding ISO/IEC or CEN/CENELEC standard27
In this scenario, consuming a carbon.txt file that links to a CSRD report alone, or even consuming a CSRD report directly would provide a reasonable basis to verify this claim.
This would not rely on any access to Green Web APIs or Datasets, and would work as a standalone project – we could have a separate validator that does the work of fetching and parsing carbon.txt files, and any linked CSRD reports within.
This approach could also be repurposed for any data likely to be in CSRD reports – while we care about how energy is sourced, covered in ESRS E1, others may care about the other standardised forms of data.
Claim 2: All the digital infrastructure we use is powered by green energy
The second scenario is a little more complicated, and likely relies on existing carbon.txt syntax more than parsing a structured CSRD report by itself.
We have two main scenarios, to cover with carbon.txt and in each case being able to parse structured data like that found in a CSRD report is of secondary importance.
In this scenario, because the CSRD does not provide explicit breakdowns to include digital infrastructure, we could not rely on the data from it alone, and have no tagged data we can search for. This would still require a degree of manual verification by Green Web of uploaded evidence.
This is not something we can verify with a standalone validator, and our existing guidance and processes would still be required.
An alternative route for sourcing data for this claim
We do know however, that a separate European directive, the Energy Efficiency Directive, requires the data we would need to substantiate this request if a company was covered by it.
This data is specified in detail already28, and while there are some get-out clauses around commercial confidentiality, there are some requirements to publicly disclose this data29.
For companies in Europe that are too small to be covered by the CSRD, but still operate significant amounts of digital infrastructure, there is a path open to support disclosing this information – however, there is no published standalone schema or taxonomy like we see published for the ESRS, that we can rely on. We would not have the same head provided by the CSRD legislation.
Verifying claims based on green energy in the supply chain
These scenarios do not try to cover claims based on green energy in supply chains, like using an external provider of digital infrastructure. This is largely because these claims would need some supporting evidence of an existing relationship with a supplier – something relying on manual review at present in the Green Web Foundation.
We cover this in more detail in the section Implementing verification with a standalone carbon.txt validator.
Acknowledgements
During this research phase we carried out semi-structured, recorded, confidential interviews with staff in technology companies responsible for preparing CSRD reports in Germany and France, as well as people involved in the creation of the reporting standards used as part of the ESRS. We also spoke to consultants who train people in affected firms who need to prepare reports, as well as people working commercially with XBRL parsing software. Our initial public call for experts to interview was published online30.
Special thanks to all those whose insights and feedback contributed to this report: Max Schulze, James Gardner, Melissa Hsiung, Betty Cremins, James Martin, Adeline Agut, Gauthier Rousillhe, Benoit Latiner, Gavin Starks, Rene Post, Laura James, Tin Gerber, Mark Action, John Booth.
Footnotes / references
- Link to The C4 model for visualising software architecture ↩︎
- See link to Searching the green web with Searx ↩︎
- See link to Searx.space ↩︎
- See link LetsEncrypt 100 million certificates issued ↩︎
- See link to Let’s Encrypt Has Issued a Billion Certificates ↩︎
- See link to the European Corporate Sustainability Reporting Directive ↩︎
- See Grant Thornton: CSRD reporting: What you need to know for a concise summary of affected entities ↩︎
- See Kabuan – CSRD: Understanding the principle of Double Materiality Assessment ↩︎
- Link to specific text mandating publishing a organisation website in CSRD Law text ↩︎
- Link to ESMA updates the European Single Electronic Format Reporting Manual ↩︎
- Link to published ESRS XBRL Taxonomy ↩︎
- Link to PWC – The bonanza of the ESG software market has started, though the best is yet to come ↩︎
- Link to XBRL Certified Software ↩︎
- Link to Workiva – Software for ESG, GRC & Financial Reporting ↩︎
- Link to Arelle – open source XBRL reporting platform ↩︎
- Link to 29th Eurofiling Conference: Using Arelle for ESRS ↩︎
- Link to EFRAG Implementation Guidance, Materiality Assessment ↩︎
- Link to In France, corporate directors can now go to jail for not complying with CSRD ↩︎
- Link to LetsEncrypt website ↩︎
- Link to Implementing carbon.txt – For Digital Service Providers ↩︎
- Link to RFC 8555 – Automatic Certificate Management Environment (ACME) ↩︎
- Link to Same Origin Policy on Wikipedia ↩︎
- Link to Observable Platform ↩︎
- Link to Observable Notebook – Create a domain hash to verify a domain is linked ↩︎
- Link to What we accept as Green Power ↩︎
- Link to ESRS E1 datapoint – Share of renewable sources in total energy consumption (%) ↩︎
- Link to ESRS 2 data point – Disclosure of extent to which data and processes that are used for sustainability reporting purposes have been verified by external assurance provider and found to conform to corresponding ISO/IEC or CEN/CENELEC standard ↩︎
- Link to Reporting requirements on the energy performance and sustainability of data centres for the Energy Efficiency Directive ↩︎
- See Happy EED day to those who celebrate. ↩︎
- Link to blog post EU Sustainability Regulation experts: can you help us? ↩︎